Lets Share Fails and Tricks with GPT
Last week, I had many interesting discussions about OpenAI and GPT on Laracon in Porto. Especially with Marcel Pociot.
I've learned much more in 2 days than on the Internet since December.
That feels great, and tips seem basic but effective. But as in any other fresh area, finding out about them takes a lot of work. I want to embrace sharing in the GPT community, so here is cherry-pick list of failures and tricks from people who were generous to share it with me.
"If you want to go fast, go alone.
If you want to go far, go together".
Are ChatGPT and GPT the same thing?
This is where I confused the people I spoke with. I thought GPT was the same as ChatGPT. But it's not. GPT is a model, ChatGPT is an online service with form that uses the GPT model.
You can use the ChatGPT from your browser here: https://chat.openai.com.

On the other hand, you can call GPT via REST API. The API is paid service, where you pay for tokens.
What is ChatGPT Pro?
It's a premium service of the online form that will run faster. It should cost 42 $.
How can I start GPT in PHP?
The go-to package in PHP is a openai-php/client created by Nuno Maduro.
composer require openai-php/client
It's a wrapper around the REST API.
$yourApiKey = getenv('YOUR_API_KEY');
$client = OpenAI::client($yourApiKey);
$result = $client->completions()->create([
'model' => 'text-davinci-003',
'prompt' => 'PHP is',
]);
// "an open-source, widely-used, server-side scripting language"
echo $result['choices'][0]['text'];
Where can I get the API token?
After you login in Openai.com, you can get the token here platform.openai.com/account/api-keys.
How much tokens is this post long?
Exactly 1 267. Every model has different limits on input content. You cannot past a whole book and expect a summary.
You can check your prompt size with official Tokenizer page: platform.openai.com/tokenizer
How fast is the Response from REST GPT API?
It depends. The shorter the prompt, the faster the response. To give you an idea, the typical TestGen AI response time is 6-10 seconds.
Well, unless the GPT is down. Then it takes longer :)
Using real-time does not make sense because the response could be faster. It's better to send the request to a background queue, let the worker handle it, and show the response when it's done.
I want to refactor TestGen AI to Livewire to address this.
Is GPT down, or is my project down?
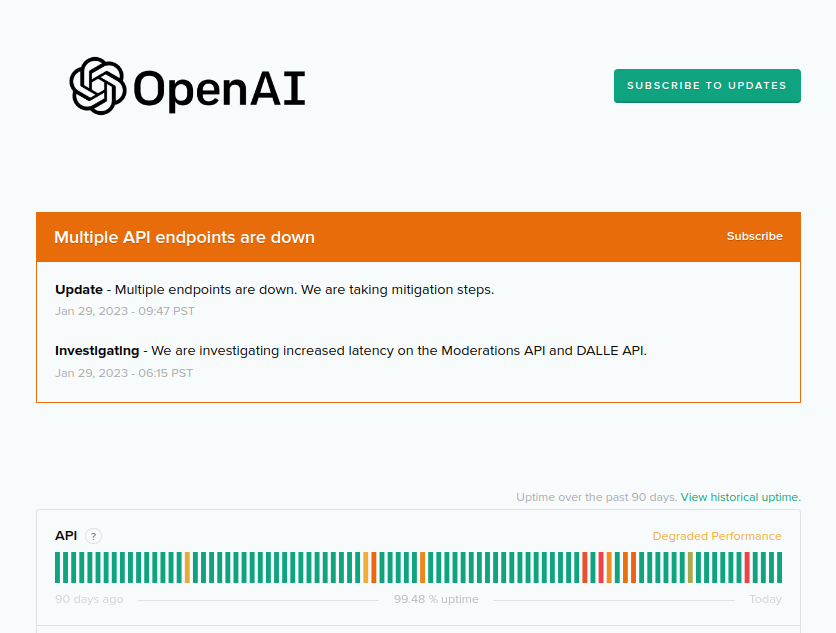
The day before the conference, TestGen AI stopped working. I didn't know if it was something on my side or if the GPT was down in general.
There is a website that tells you the answer: status.openai.com:
How does Copilot work with Context Files?
This is a bit advanced topic, but it could be helpful, so I put it here. The longer you use the GPT, the more you see that the context is everything.
E.g., let's say we want to ask GPT to generate a unit test for the ConferenceFactory class. This class has a dependency in the constructor - a TalkFactory and SpeakerRepository. To make GPT works the best, you should provide these files too.
This is similar to the way GitHub Copilot works - it has a context of your project (not a whole, but some files), and it uses it to generate more tailored code. Here is how Copilot Internals.
In the next post, we'll look at the 2 different models and how to treat them right.
Let's share!
- What have you found out about GPT?
- What is a blind way to go?
- How do you use it via REST API?
Let me know in the comments or share on Twitter with #GPTtips. I believe we can learn a lot from each other and reach our goals faster.
Happy coding!
